|
Applied Scientist, AWS AI Lab | RL for LLM Agents and Code Agents I am an Applied Scientist at AWS AI Lab, where I work on RL and post-training for agentic LLMs, with a focus on multi-turn tool-integrated reasoning and code agents, including Kiro and Amazon Q. I received my Ph.D. from Columbia University, advised by Prof. Xuan Di and Prof. Elias Bareinboim. Before Columbia, I received my Master's degree from Carnegie Mellon University in 2020. My research interests include RL for LLM agents, agentic post-training, RLHF/RLAIF/RLEF, tool-integrated reasoning, code generation, and causality. Representative papers are highlighted. Email / CV (last updated: July 2023) / LinkedIn / Google Scholar |

|
News
| 2026/05 - Our paper on "Empowering Multi-Turn Tool-Integrated Agentic Reasoning with Group Turn Policy Optimization" was accepted to the ACL 2026 Main Conference. |
| 2024/12 - Our paper on "Causal Imitation for Markov Decision Processes: A Partial Identification Approach" was published at NeurIPS 2024. |
| 2024/08 - Our paper on LLMs and mobility travel modes was published at ITSC 2024. |
| 2023/12 - Our paper on multimodal entity resolution and LLMs, completed at Amazon, was published at ICASSP 2024. |
| 2023/05 - Joined Amazon Artificial General Intelligence (AGI) team as an Applied Scientist summer intern. |
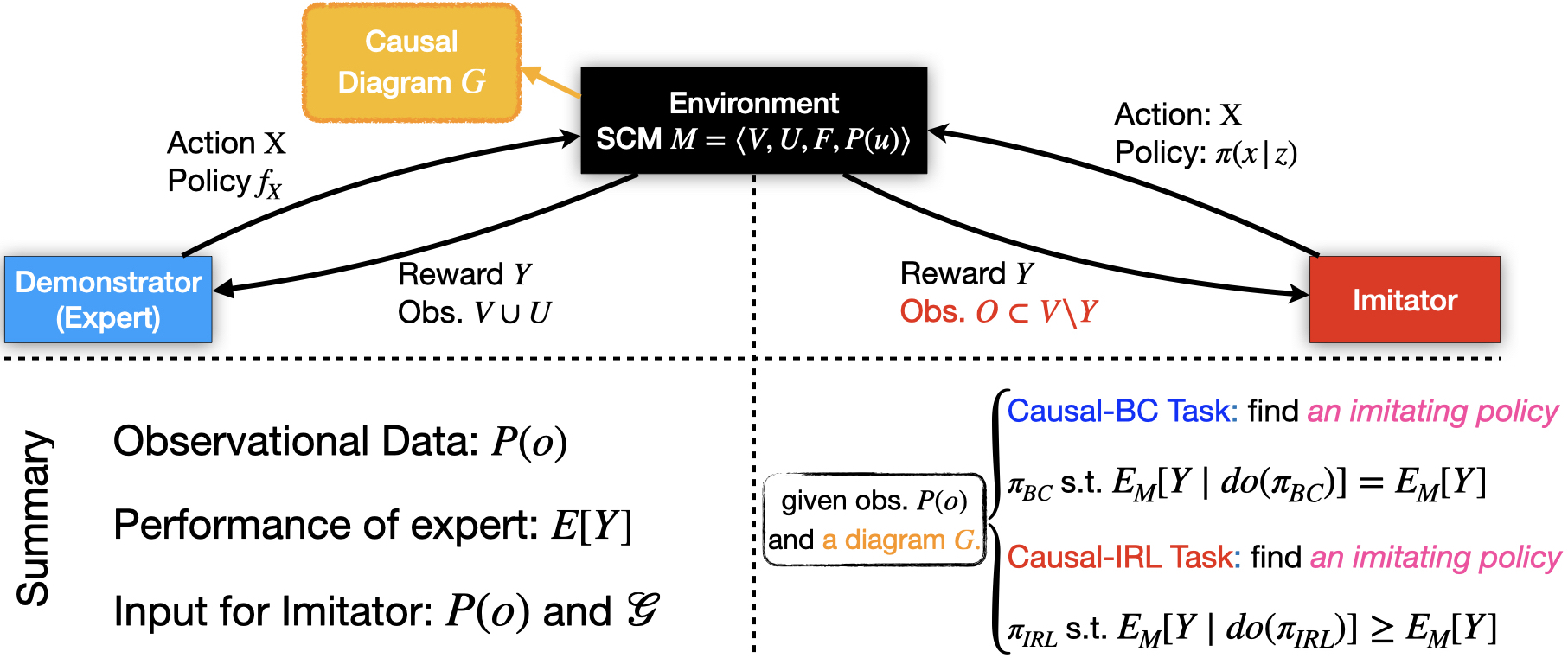
| 2023/01 - Our paper on "Causal Imitation Learning via Inverse Reinforcement Learning" was published at ICLR 2023. |
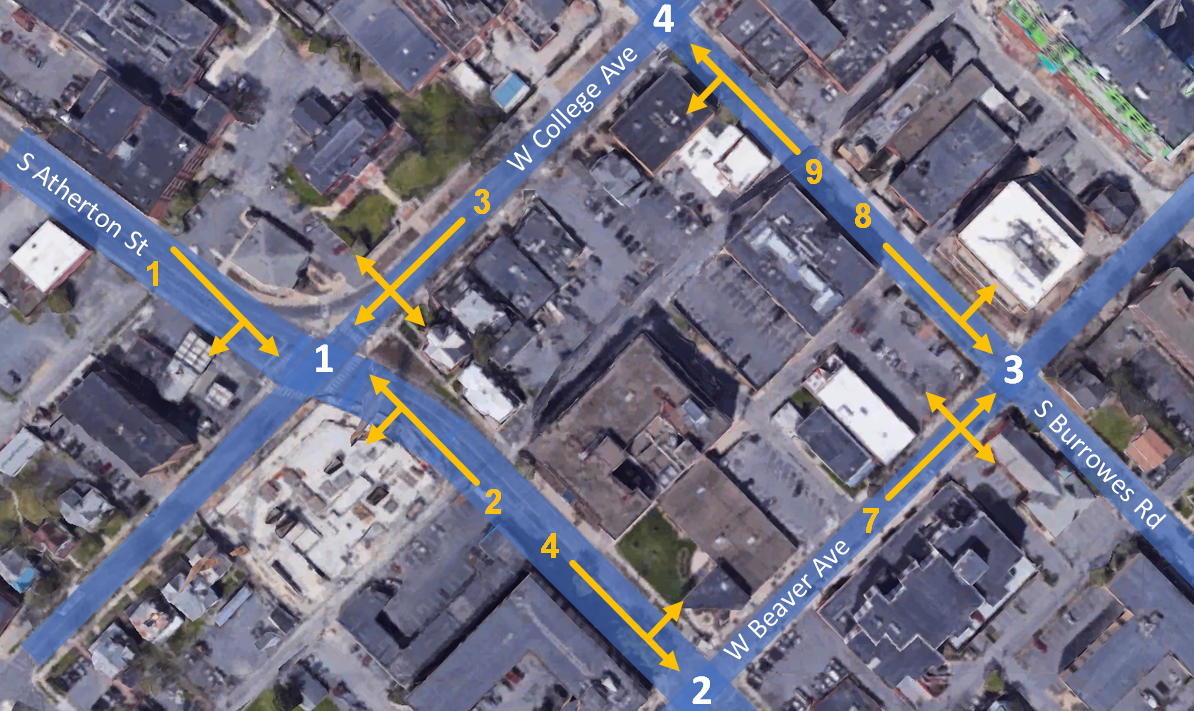
| 2022/08 - Our paper on decentralized traffic signal control was published in Transportation Research Part C. |
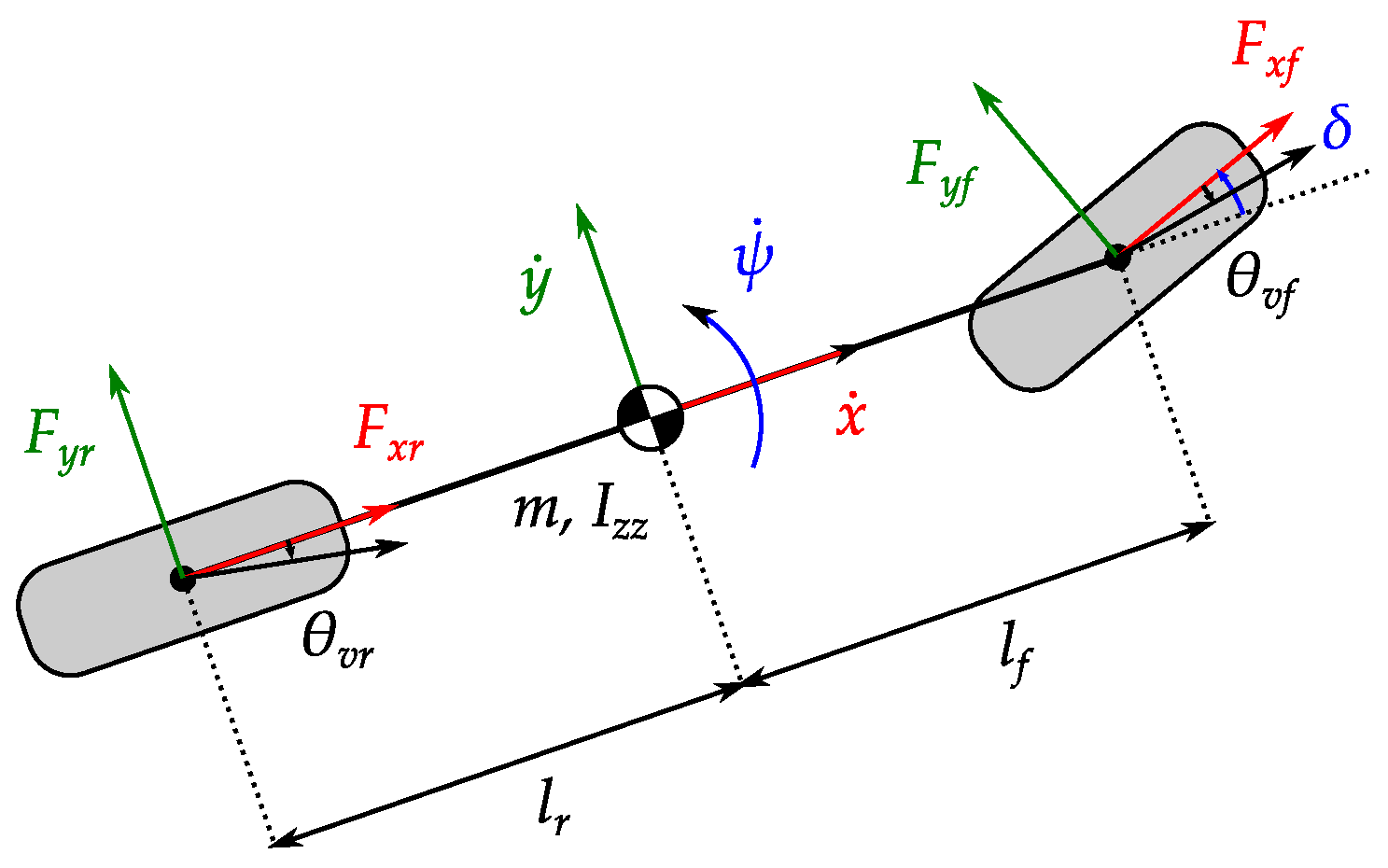
| 2022/06 - Our paper on integrated safety-enhanced RL and MPC was published in Transportation Research Part C. |
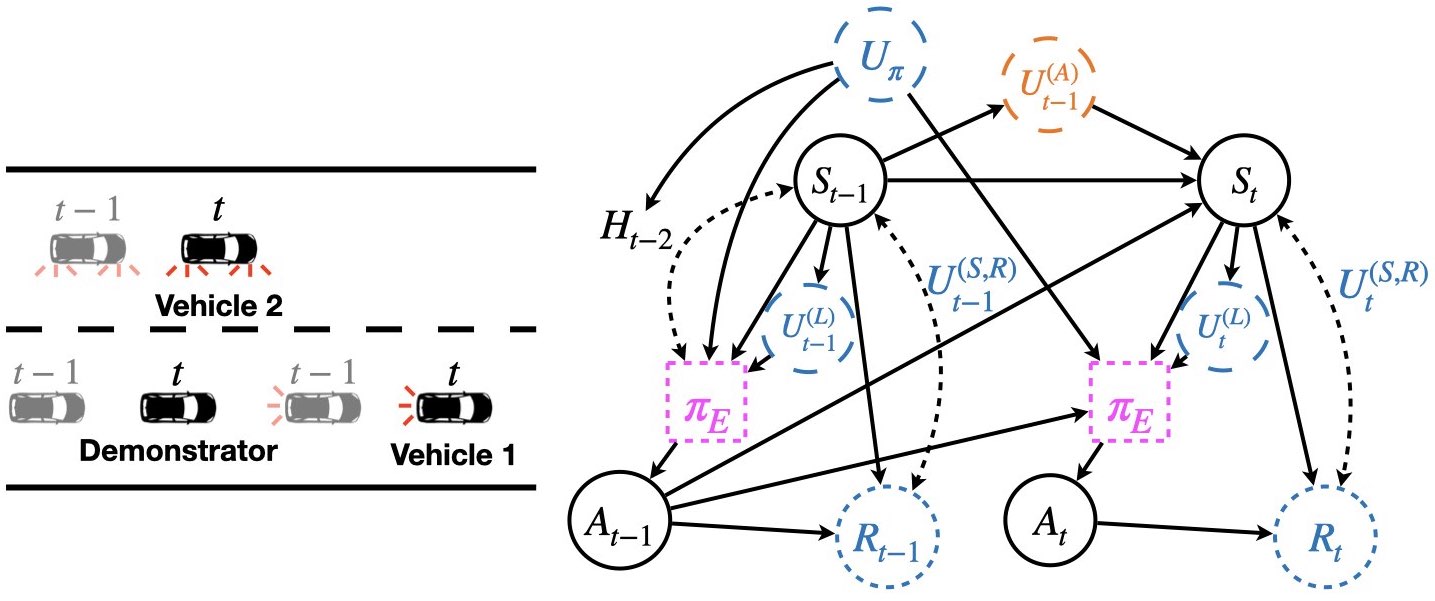
| 2022/05 - Our paper on "Learning Human Driving Behaviors with Sequential Causal Imitation Learning" was published at AAAI 2022. |
Selected Publications
|
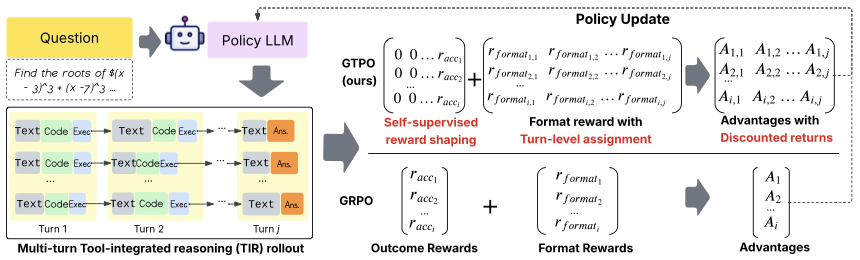
ACL 2026 Main Conference [paper] Training LLMs for multi-turn Tool-Integrated Reasoning (TIR) remains challenging for existing RL approaches. We propose Group Turn Policy Optimization (GTPO), a novel RL algorithm specifically designed for training LLMs on multi-turn TIR tasks. GTPO introduces turn-level reward assignment, return-based advantage estimation, and self-supervised reward shaping to densify sparse binary outcome-based rewards. Our evaluation shows that GTPO outperforms GRPO across math reasoning, commonsense reasoning, and program synthesis tasks while incurring negligible overhead. |

|
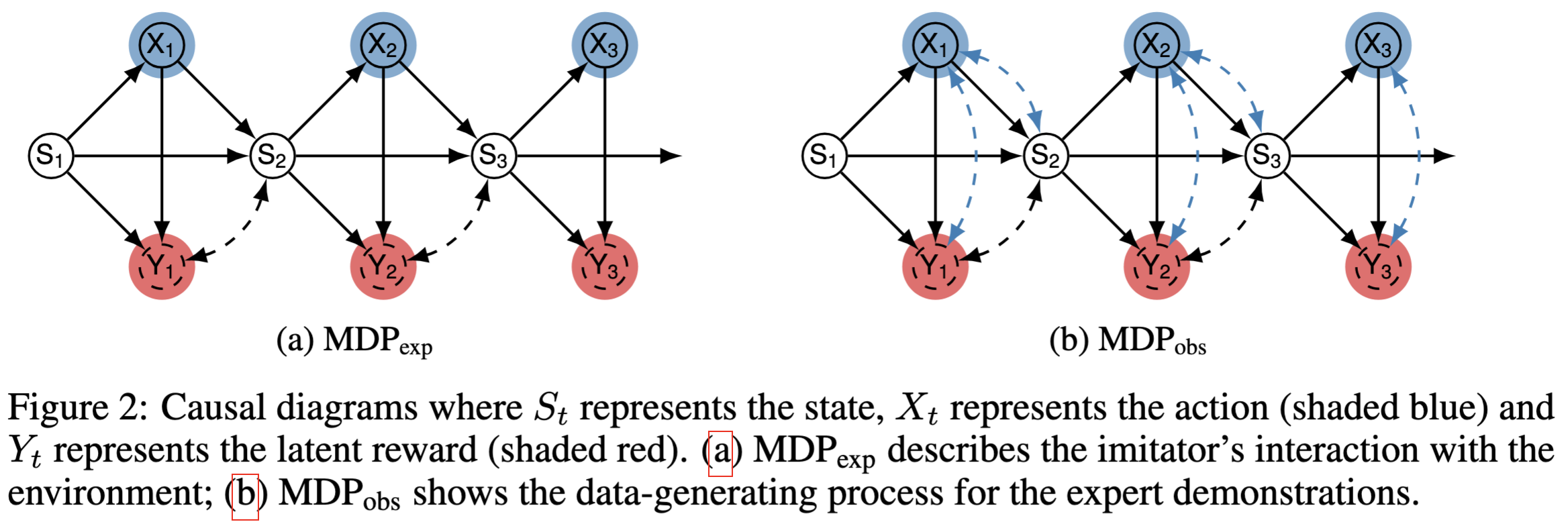
NeurIPS 2024 [paper] In this paper, we investigate robust imitation learning within the framework of canonical Markov Decision Processes (MDPs) using partial identification, allowing the agent to achieve expert performance even when the system dynamics are not uniquely determined from the confounded expert demonstrations. Specifically, we first theoretically demonstrate that when unobserved confounders (UCs) exist in an MDP, the learner is generally unable to imitate expert performance. |
|
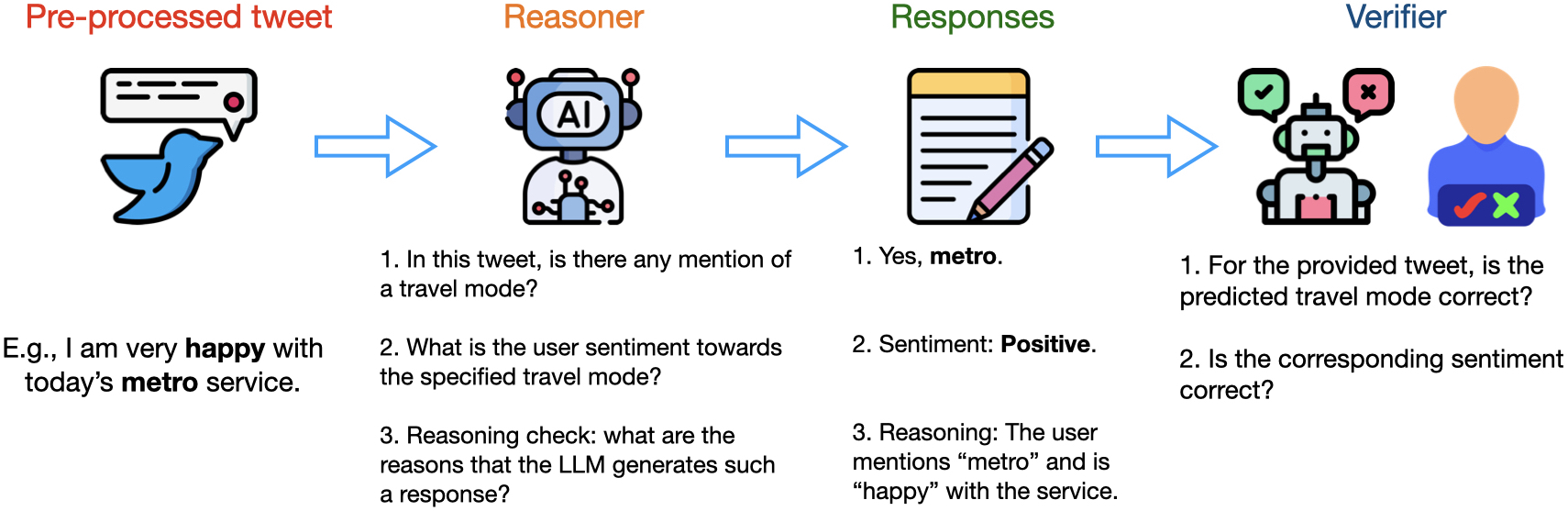
IEEE ITSC 2024 [paper] In this study, we introduce a novel methodological framework using LLMs to infer the mentioned travel modes from social media posts, and reason people's attitudes toward the associated travel mode, without the need for manual annotation. We compare different LLMs along with various prompting engineering methods in light of human assessment and LLM verification. |
|
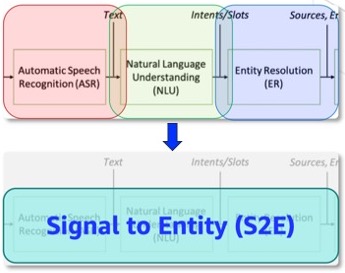
2024 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2024 [paper] Traditional cascading Entity Resolution (ER) pipeline suffers from propagated errors from upstream tasks. We address this issue by formulating a new end-to-end (E2E) ER problem, Signal-to-Entity (S2E), resolving query entity mentions to actionable entities in textual catalogs directly from audio queries instead of audio transcriptions in raw or parsed format. |
|
The Eleventh International Conference on Learning Representations, ICLR 2023 [paper] This paper has 2 key contributions. First, the paper analyzes structural conditions on the causal model under which learning the expert policy is possible in the presence of unobserved confounding. Second, the authors further exploit knowledge of the graphical structure to extend IRL algorithms such as GAIL or MWAL to the confounded settings. |
|
The 36th AAAI Conference on Artificial Intelligence, AAAI 2022 [paper] [code] We develop a sequential causal template that generalizes the default MDP settings to one with Unobserved Confounders (MDPUC-HD). |
|
Transportation Research Part C: Emerging Technologies, 2022 [paper] This paper develops an integrated safety-enhanced RL and MPC framework for autonomous vehicles (AVs) to navigate unsignalized intersections. |
|
Transportation Research Part C: Emerging Technologies, 2022. [paper] This paper develops a decentralized RL scheme for multi-intersection adaptive traffic signal control (TSC), called “CVLight”, that leverages data collected from connected vehicles (CVs). |